
WordPress crea automáticamente una página pública indexable por cada etiqueta que añades a tus artículos. Eso significa que si tu blog tiene 200 artículos con 5 etiquetas cada uno, estás generando potencialmente cientos de URLs adicionales que Google puede rastrear, indexar y evaluar. En la mayoría de casos, esas páginas están vacías de contenido real, no tienen intención de búsqueda clara y aportan cero valor al usuario.
El problema no es WordPress en sí, sino cómo se usan estas taxonomías sin criterio SEO. Muchos proyectos acumulan durante años etiquetas duplicadas, redundantes o generadas casi en automático, sin que nadie haya revisado el impacto que tienen sobre la arquitectura web y el posicionamiento. Es uno de esos problemas silenciosos que los expertos en SEO técnico detectan constantemente en auditorías de sitios que no terminan de escalar.
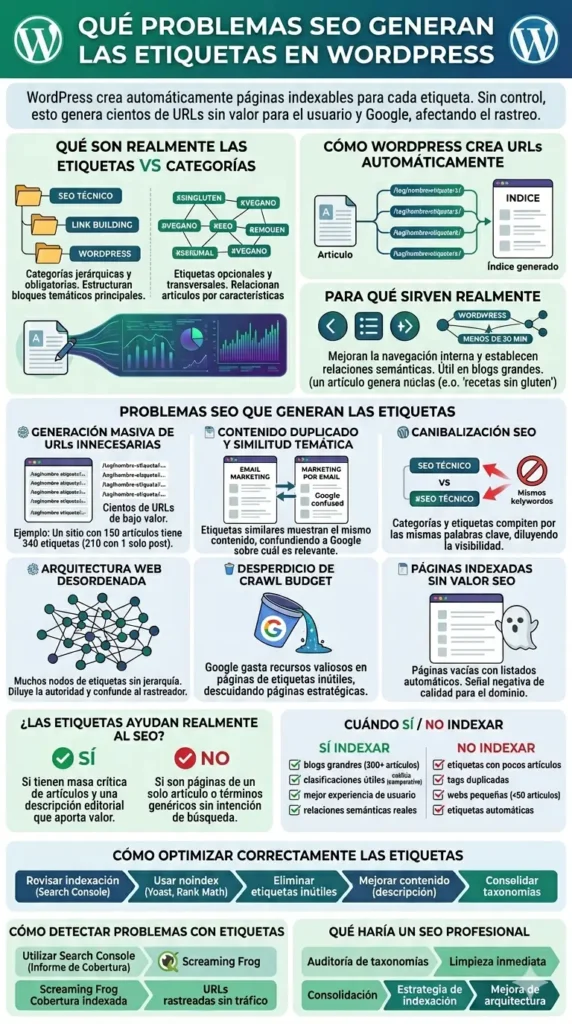
Qué son realmente las etiquetas en WordPress
Diferencia entre categorías y etiquetas
Las categorías en WordPress son jerárquicas y obligatorias: estructuran el contenido en bloques temáticos principales. Un blog puede tener categorías como «SEO técnico», «Link building» o «WordPress», y esa estructura refleja la arquitectura temática del sitio.
Las etiquetas son taxonomías planas, opcionales y transversales. Se usan para señalar características concretas de un artículo que no encajan en la jerarquía de categorías. En teoría, sirven para relacionar artículos por aspectos específicos. En la práctica, se usan con muy poca coherencia.
Cómo WordPress crea URLs automáticamente
Cada vez que creas una etiqueta y la asignas a un artículo, WordPress genera automáticamente una URL del tipo /tag/nombre-etiqueta/. Esa página lista todos los artículos que tienen esa etiqueta. Si la etiqueta solo tiene un artículo, la página muestra prácticamente el mismo contenido que el propio artículo: título, extracto o contenido completo según el tema activo.
Para qué sirven realmente
Las etiquetas tienen sentido como herramienta de navegación interna y para establecer relaciones semánticas entre contenidos. Un blog de gastronomía con cientos de recetas puede usarlas bien: etiqueta «sin gluten», etiqueta «menos de 30 minutos», etiqueta «vegano». Pero incluso en esos casos, la decisión de indexarlas o no debe tomarse con criterio. Una estrategia sólida de categorías SEO en el blog siempre va antes que cualquier decisión sobre etiquetas.
Problemas SEO que generan las etiquetas mal utilizadas
Esta es la parte que importa. Los problemas que siguen afectan a miles de sitios WordPress activos ahora mismo.
Generación masiva de URLs innecesarias
El escenario más habitual: un blog con años de actividad que ha ido acumulando etiquetas sin control. Etiquetas con un solo artículo asignado, etiquetas con nombres similares («SEO», «seo técnico», «tecnico-seo»), etiquetas que se crearon por error y nunca se borraron.
Cada una genera su URL. Una URL con un único artículo listado no ofrece nada que no tenga ya la propia página del artículo. Son páginas thin content puras: escaso contenido, sin intención de búsqueda clara, sin enlazado interno relevante y sin posibilidad real de posicionar para nada.
Ejemplo real: una web de marketing digital con 150 artículos tiene 340 etiquetas activas. De esas, 210 solo tienen un artículo asignado. Eso son 210 URLs innecesarias que Google puede rastrear e indexar.
Contenido duplicado y similitud temática
Cuando dos etiquetas son semánticamente muy parecidas («email marketing» y «marketing por email», «link building» y «construcción de enlaces»), sus páginas de archivo listan prácticamente los mismos artículos. Google encuentra dos URLs con el mismo contenido y no tiene criterio claro para decidir cuál es más relevante.
Esto no solo genera contenido duplicado entre las propias páginas de etiquetas, sino también similitud con los artículos que listan. Si una etiqueta reproduce el extracto completo de un artículo, hay solapamiento de contenido entre dos URLs del mismo dominio. El resultado es dilución de señales y pérdida de claridad semántica. Este problema está directamente relacionado con los casos que se analizan al detectar y solucionar duplicidad técnica en SEO.
Canibalización SEO
Cuando una etiqueta ataca la misma intención de búsqueda que una categoría o que un artículo del blog, tienes un problema de canibalización SEO. Google no sabe qué URL posicionar para esa búsqueda y puede alternar entre ellas, reduciendo la visibilidad de ambas.
Ejemplo: tienes una categoría «SEO técnico» y una etiqueta «seo técnico». Ambas generan páginas indexadas con contenidos similares y compiten por las mismas keywords. Esto confunde al rastreador y perjudica a la URL que realmente querías posicionar. Si sospechas que esto ocurre en tu sitio, conviene saber cómo detectar y corregir la canibalización antes de que frene tu posicionamiento.
Arquitectura web desordenada
Una web con categorías bien definidas más decenas de etiquetas activas genera una arquitectura caótica. El enlazado interno se distribuye entre demasiados nodos sin jerarquía clara, los clústeres temáticos se difuminan y Google tiene dificultades para entender cuáles son las páginas más importantes del sitio.
Las taxonomías WordPress no son solo una cuestión de organización del contenido: definen la estructura de autoridad interna del dominio. Cuantas más URLs de archivo indexadas sin valor existan, más fragmentada queda esa autoridad.
Desperdicio de crawl budget
El crawl budget es la cantidad de URLs que Googlebot está dispuesto a rastrear en tu sitio en un periodo determinado. En sitios medianos y grandes, este recurso es finito. Si Google gasta parte de ese presupuesto rastreando páginas de etiquetas con un solo artículo y sin ningún valor, lo hace a costa de rastrear peor las páginas que realmente importan.
Esto retrasa la indexación de contenido nuevo, ralentiza la propagación de cambios y reduce la frecuencia de rastreo de las URLs estratégicas. Es un problema que se aborda en detalle cuando se analiza qué es el crawl budget y cómo afecta al SEO.
Páginas indexadas sin valor SEO
Una página de etiqueta con un solo post, sin descripción, sin contenido editorial propio y con un extracto automático generado por el tema de WordPress es una señal negativa para Google. Son páginas que no responden ninguna búsqueda real, no retienen al usuario y no generan ningún valor.
Si Google indexa muchas de estas páginas en tu dominio, deteriora la percepción general de calidad del sitio. Esto puede contribuir a una indexación lenta o deficiente de las páginas que sí importan.
¿Las etiquetas ayudan realmente al SEO?
Depende completamente de cómo se usen. Una etiqueta con 20 artículos bien relacionados, un nombre con intención de búsqueda real y una descripción editorial propia puede posicionar y generar tráfico. Una etiqueta con un solo artículo, sin descripción y con un nombre genérico es ruido puro.
La regla práctica es clara: si una página de etiqueta no puede responder una búsqueda real de forma mejor que los propios artículos que la componen, no debería estar indexada.
Cuándo tiene sentido usar etiquetas en WordPress
Blogs grandes
Un blog con más de 300 artículos sobre temas amplios puede beneficiarse de etiquetas como capa adicional de organización y relación entre contenidos. Siempre que esas etiquetas tengan suficiente masa crítica de artículos y una intención de búsqueda definida.
Clasificaciones útiles
Cuando la etiqueta representa una característica transversal que las categorías no pueden capturar bien. En un blog de tecnología con categorías por tema (hardware, software, móviles), una etiqueta como «análisis comparativo» o «guía de compra» puede cruzar categorías de forma coherente.
Experiencia de usuario
Las etiquetas ayudan al usuario a navegar entre contenidos relacionados. Si alguien lee un artículo sobre Python y ve etiquetas como «automatización» o «scripting», puede encontrar más contenido relevante. Eso reduce la tasa de rebote y mejora las señales de comportamiento.
Relaciones semánticas reales
Cuando los artículos comparten un subtema específico que merece agrupación, las etiquetas bien usadas refuerzan la coherencia semántica del sitio y contribuyen al clúster temático.
Cuándo NO deberías indexar etiquetas
Etiquetas con pocos artículos
Cualquier etiqueta con menos de 5-8 artículos asignados debería estar en noindex. No tiene masa crítica suficiente para ofrecer valor como página de archivo.
Tags duplicadas
Si tienes etiquetas que son variaciones del mismo concepto («ecommerce», «e-commerce», «tienda online»), están generando contenido duplicado. Deben consolidarse o eliminarse.
Webs pequeñas
Un sitio con menos de 50 artículos no necesita etiquetas indexadas. Las categorías son suficientes para organizar el contenido y la arquitectura es lo suficientemente pequeña como para no necesitar otra capa taxonómica.
Etiquetas automáticas
Algunos plugins o flujos de trabajo generan etiquetas de forma automática a partir del contenido. Estas etiquetas suelen ser inconsistentes, redundantes y sin ningún criterio SEO. Deben bloquearse o desindexarse siempre.
Cómo optimizar correctamente las etiquetas
Revisar indexación
El primer paso es saber exactamente cuántas páginas de etiquetas tiene el sitio indexadas y cuánto tráfico orgánico reciben. Muchos proyectos descubren aquí que tienen cientos de URLs indexadas con cero visitas en los últimos 12 meses.
Usar noindex
La solución más rápida y segura para etiquetas sin valor es añadir la directiva noindex a través de Yoast SEO, Rank Math u otro plugin SEO. Así Google deja de indexarlas sin necesidad de eliminarlas ni redirigirlas.
Eliminar etiquetas inútiles
Las etiquetas con un solo artículo, las duplicadas y las creadas por error deben eliminarse. WordPress redirige automáticamente la URL de una etiqueta eliminada si estaba bien configurada, o se puede hacer manualmente con un plugin de redirecciones.
Mejorar contenido
Para las etiquetas que sí tienen potencial SEO (volumen de búsqueda, masa crítica de artículos), vale la pena añadir una descripción editorial de calidad. Ese texto convierte la página de etiqueta de un simple archivo en una página con contenido propio.
Consolidar taxonomías
En muchos casos la solución es reducir el número de etiquetas activas a un subconjunto manejable y con sentido estratégico. Esta consolidación forma parte de cualquier auditoría seria de arquitectura web. Herramientas como Screaming Frog facilitan enormemente este proceso; puedes ver cómo usarla en esta guía de auditoría SEO con Screaming Frog.
Cómo detectar problemas SEO causados por etiquetas
Search Console
Filtra las URLs por prefijo /tag/ en el informe de Cobertura. Verás cuántas están indexadas, cuáles tienen errores y cuántas tienen impresiones o clics reales. Si hay cientos de páginas de etiquetas indexadas con cero impresiones, tienes un problema.
Screaming Frog
Rastrea el sitio y filtra por URLs que contengan /tag/. Identifica cuántas hay, cuántos enlaces internos reciben y si tienen etiqueta canonical o noindex. También detecta etiquetas huérfanas o con muy pocos artículos.
Cobertura indexada
En Search Console, el informe de Cobertura muestra las páginas que Google ha indexado. Un porcentaje alto de páginas de etiquetas en el índice frente a páginas de contenido real es una señal de arquitectura mal gestionada.
URLs rastreadas sin tráfico
Cualquier URL que Google rastrea regularmente pero que no genera ningún tráfico orgánico es candidata a revisión. Las páginas de etiquetas suelen aparecer masivamente en este filtro. Si tienes un proyecto de desarrollo web activo, este tipo de auditoría debería hacerse antes del lanzamiento, no después.
Qué haría un SEO profesional
Un SEO técnico con experiencia ante un proyecto WordPress con etiquetas mal gestionadas seguiría este proceso:
- Auditoría de taxonomías: extrae todas las URLs
/tag/del sitio, cruza con datos de Search Console y Screaming Frog para ver cuántas están indexadas, cuántas tienen tráfico y cuántas son candidatas directas a noindex o eliminación. - Limpieza inmediata: noindex en todas las etiquetas sin tráfico orgánico en los últimos 12 meses y con menos de 5 artículos asignados. Esto solo ya puede reducir un 60-80% del problema.
- Consolidación: fusionar etiquetas duplicadas o muy similares en una sola, redirigiendo las eliminadas.
- Estrategia de indexación: definir criterios claros sobre qué etiquetas pueden indexarse en el futuro y cuáles no. Documentarlo para que el equipo de contenidos no vuelva a generar el mismo problema.
- Mejora de arquitectura: revisar que las categorías principales están bien estructuradas y reciben el enlazado interno adecuado, sin competencia ni solapamiento con etiquetas indexadas.
Este proceso no es complejo, pero requiere criterio. La mayoría de problemas con etiquetas en WordPress se deben a decisiones tomadas hace años sin pensar en SEO, y se resuelven en pocas semanas con una auditoría bien hecha.
Preguntas frecuentes sobre etiquetas WordPress y SEO
¿Es mejor usar categorías o etiquetas para el SEO?
Las categorías son casi siempre más valiosas desde el punto de vista SEO porque crean una jerarquía temática clara que Google puede interpretar. Las etiquetas son complementarias y opcionales. Si tienes que elegir en qué invertir esfuerzo editorial, prioriza siempre las categorías.
¿Google indexa automáticamente las páginas de etiquetas?
Sí, salvo que estén bloqueadas con noindex o en el archivo robots.txt. WordPress las genera y las expone públicamente por defecto. Si no has tomado ninguna decisión activa al respecto, probablemente estén indexadas.
¿Yoast SEO permite desindexar etiquetas fácilmente?
Sí. En Yoast SEO, dentro de «Apariencia en buscadores > Taxonomías», puedes desactivar la indexación de todas las páginas de etiquetas con un solo toggle. Rank Math tiene una opción equivalente. Es una de las primeras configuraciones que debería revisarse en cualquier instalación WordPress nueva.
¿Las etiquetas afectan al presupuesto de rastreo de mi sitio?
Directamente. Googlebot rastrea las URLs que encuentra, y las páginas de etiquetas reciben enlaces automáticos desde los artículos del blog. Un sitio con 500 páginas de etiquetas innecesarias está obligando a Googlebot a gastar rastreo en URLs sin valor, en detrimento de las páginas que sí importan.
¿Cuántas etiquetas debería tener un artículo?
Entre 2 y 5 etiquetas por artículo es un rango razonable, siempre que esas etiquetas existan de forma deliberada en la estrategia del blog y tengan suficiente masa crítica. Lo que hay que evitar es crear etiquetas nuevas para cada artículo o asignar 10-15 etiquetas distintas de forma sistemática.
Un comentario