
Screaming Frog es un rastreador web de escritorio que simula el comportamiento de Googlebot para analizar la estructura técnica de cualquier sitio web. En menos de una hora puede darte una radiografía completa de los errores SEO que frenan el posicionamiento de una web: URLs rotas, contenido duplicado, canonicals mal configurados, páginas huérfanas, redirecciones en cadena y decenas de problemas técnicos que Google ve pero tú no.
Es la herramienta más utilizada por profesionales del SEO técnico en todo el mundo, no porque sea la única, sino porque ninguna otra combina tanta profundidad de datos con tanta flexibilidad de configuración. Si trabajas el posicionamiento web de forma seria —ya sea en una agencia especializada en SEO, como freelance o gestionando tu propio sitio— dominar Screaming Frog es imprescindible.
🛠️ Cómo configurar Screaming Frog antes de empezar
Instalación
Screaming Frog SEO Spider está disponible para Windows, macOS y Ubuntu. El proceso de instalación es estándar y no requiere configuración especial en la mayoría de sistemas. Una vez instalado, al abrirlo por primera vez verás la interfaz principal con la barra de URL en la parte superior.
Versión gratuita vs de pago
La versión gratuita permite rastrear hasta 500 URLs por proyecto, lo que es suficiente para webs pequeñas o para hacer pruebas iniciales. A partir de 500 URLs necesitas la licencia de pago, que cuesta alrededor de 259 £ al año e incluye funciones avanzadas: rastreo ilimitado, integración con Google Analytics 4, Search Console y PageSpeed Insights, comparación entre rastreos y exportación completa de datos.
| Característica | Versión gratuita | Versión de pago |
|---|---|---|
| Límite de URLs | 500 | Ilimitado |
| Integración GA4/GSC | ❌ | ✅ |
| Comparación de rastreos | ❌ | ✅ |
| JavaScript rendering | Limitado | Completo |
| Exportación de datos | Parcial | Completa |
Configuración básica
Antes de lanzar cualquier rastreo, accede a Configuration → Spider y ajusta estos parámetros: activa el rastreo de imágenes, JavaScript, CSS y hreflang si los necesitas. En Configuration → Crawl Depth puedes limitar la profundidad máxima si solo quieres analizar ciertos niveles del sitio.
Límites de rastreo
Para sitios grandes, ajusta la velocidad en Configuration → Speed para no saturar el servidor. Un ritmo de 5 a 10 peticiones por segundo es razonable en la mayoría de casos. Si el servidor es lento o el sitio está en un hosting compartido, bájalo a 2 o 3.
User-Agent
Por defecto, Screaming Frog se identifica como Screaming Frog SEO Spider. Si quieres simular exactamente cómo ve el sitio Googlebot, cambia el User-Agent en Configuration → User-Agent → Googlebot. Esto es útil cuando sospechas que el servidor responde de forma diferente a los bots.
Configuración de Java y memoria
Screaming Frog funciona sobre Java. Si rastreas sitios grandes (más de 100.000 URLs), puede quedarse sin memoria y bloquearse. Para evitarlo, ve a Help → SEO Spider Settings → System y aumenta la memoria asignada. En webs muy grandes, asignar 2 o 4 GB es habitual.
🔍 Cómo hacer el primer rastreo de una web
Introducir el dominio
Escribe la URL raíz del sitio (con https://) en la barra superior y pulsa Start. Screaming Frog comenzará a rastrear desde esa URL y seguirá todos los enlaces internos que encuentre.
Configurar el crawl
Si quieres rastrear solo una sección del sitio (por ejemplo, el blog o una categoría de ecommerce), usa Configuration → Include para limitar el rastreo a esa ruta. Si quieres excluir ciertas secciones, usa Configuration → Exclude.
Qué ocurre durante el rastreo
Mientras rastrea, verás cómo se van cargando URLs en tiempo real en la pestaña Internal. La barra inferior muestra el número total de URLs encontradas, las rastreadas, las en cola y la velocidad actual. En sitios medianos (entre 1.000 y 10.000 URLs) el rastreo completo puede tardar entre 5 y 20 minutos dependiendo de la velocidad del servidor y la configuración.
Cómo interpretar el panel principal
Al finalizar, el panel superior muestra un resumen con el total de URLs internas, el número de errores por tipo y las métricas más relevantes. Las pestañas de la parte superior son el núcleo del análisis: cada una corresponde a un área específica del rastreo web. Lo que vas a ver a continuación es exactamente qué mirar en cada una.
📂 Pestañas importantes de Screaming Frog
🟢 Internal
Esta pestaña muestra todas las URLs internas encontradas durante el rastreo. Es el punto de partida de cualquier auditoría SEO.
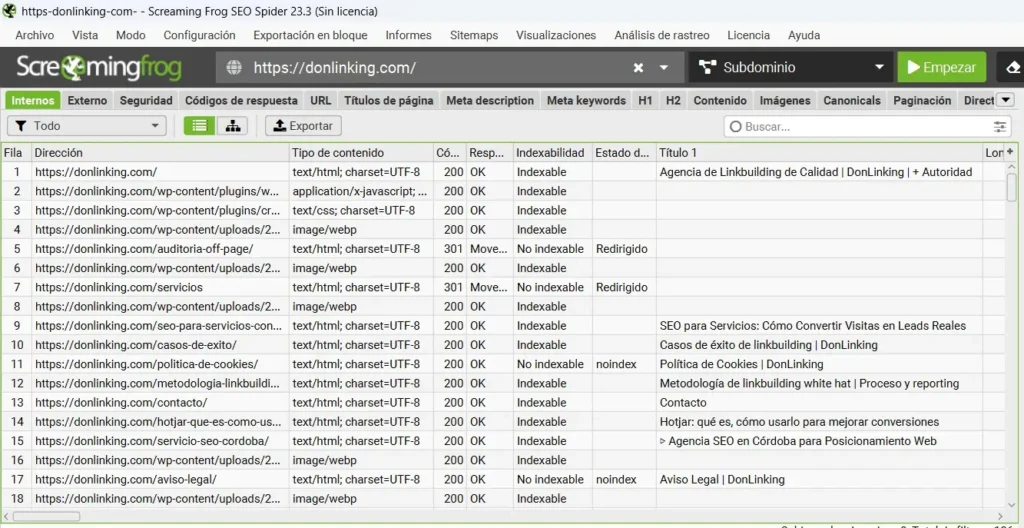
Qué revisar aquí:
- Status codes: filtra por código para ver qué URLs responden con 200 (OK), 301, 302, 404 o 5xx.
- Indexabilidad: la columna Indexability indica si Google puede indexar esa URL. Valores como «Noindexed», «Canonicalised» o «Blocked by robots.txt» son señales de alerta.
- Click Depth: indica a cuántos clics está cada URL desde la home. Las páginas importantes no deberían estar a más de 3 clics. Si tienes páginas clave a 6 o 7 clics, Google las rastreará con menor frecuencia.
- URL Length: URLs muy largas (más de 115 caracteres) pueden generar problemas. Filtra y revisa.
- Response Time: detecta páginas lentas. Cualquier URL que supere los 2 segundos merece atención.
Problemas típicos que aparecen aquí: URLs de parámetros indexadas sin necesidad, páginas de búsqueda interna visibles para Google, URLs de paginación sin gestión correcta y páginas con escaso contenido que consumen crawl budget sin aportar valor.
🔴 Response Codes
Esta pestaña agrupa todas las URLs por su código de respuesta HTTP. Es donde detectas los problemas de accesibilidad más críticos.
200 OK: respuesta correcta. No siempre significa que la página esté bien —puede tener contenido duplicado, thin content o estar noindexada— pero al menos es accesible.
301 Moved Permanently: redirección permanente. Correcta cuando es necesaria, problemática cuando se encadena. Una cadena de redirecciones (A → B → C) pierde autoridad en cada salto. Lo ideal es que todas las redirecciones vayan directamente al destino final.
302 Found: redirección temporal. Google no traspasa autoridad de forma consistente con las 302. Si usas una 302 donde debería haber una 301, estás perdiendo link juice sin saberlo. Entender la diferencia entre ambas es clave: puedes profundizar en cómo afectan al posicionamiento en este artículo sobre redirecciones 301 y 302 en SEO.
404 Not Found: página no encontrada. Diferencia entre 404 internos (páginas de tu web que enlazan a una URL que no existe) y 404 externos (backlinks apuntando a URLs eliminadas). Los primeros los resuelves corrigiendo el enlace. Los segundos pueden necesitar una redirección si la página tenía autoridad.
5xx Server Error: errores de servidor. Si Screaming Frog encuentra URLs con 500, 502 o 503, hay un problema en el servidor que impide a Google acceder correctamente. Prioritario.
🟡 Page Titles
Aquí ves todos los títulos SEO del sitio y sus problemas:
- Duplicate: varios títulos idénticos en páginas distintas. Google no sabe cuál priorizar y puede ignorar ambas.
- Over X Characters: títulos que superan los 60 caracteres y se truncan en las SERPs. Ejemplo problemático: «Servicios de diseño web profesional en Madrid con más de 20 años de experiencia» (82 caracteres).
- Missing: páginas sin título. Cualquier página indexable sin title es un error grave.
- Below X Characters: títulos demasiado cortos que desaprovechan el espacio disponible para posicionar.
Filtra por «Duplicate» y ordena por número de apariciones. Si tienes 50 páginas de categoría con el título «Categoría – NombreWeb», tienes un problema de optimización masivo.
🟠 Meta Description
La meta descripción no es un factor de ranking directo, pero sí influye en el CTR y Google la usa cuando le parece relevante.
- Missing: páginas sin meta description. Google generará una automáticamente y casi siempre será peor que una escrita a mano.
- Duplicate: si tienes la misma meta en múltiples páginas, pierdes la oportunidad de diferenciarte en las SERPs.
- Over 155 characters: se truncará en los resultados. Ajusta a entre 140 y 155 caracteres.
🔵 H1 y H2
- Missing H1: cualquier página indexable sin H1 está desaprovechando una señal de relevancia básica.
- Multiple H1: tener más de un H1 en la misma página genera confusión sobre el tema principal.
- Duplicate H1: igual que con los títulos, H1 repetidos entre páginas distintas diluyen la señal temática.
- Missing H2: no es un error crítico, pero una página sin estructura de encabezados es más difícil de procesar para Google y para el usuario.
🟣 Canonicals
Los canonicals son una de las partes más delicadas del SEO técnico y donde más errores se producen.
- Canonical correcto: la página A tiene un canonical apuntando a sí misma (
<link rel="canonical" href="https://web.com/pagina-a/">). Todo correcto. - Canonical roto: el canonical apunta a una URL que no existe o que devuelve 404. Google ignora el canonical y toma sus propias decisiones.
- Canonical cruzado: la página A dice que el canonical es la página B, pero la página B dice que el canonical es la página A. Situación contradictoria que Google no puede resolver.
- Canonicalización incorrecta: páginas con buen contenido original que tienen un canonical apuntando a otra URL. Resultado: Google indexa la segunda y la primera pierde toda su visibilidad.
Los canonicals están directamente relacionados con los problemas de duplicidad técnica, que afectan al posicionamiento de forma silenciosa y progresiva.
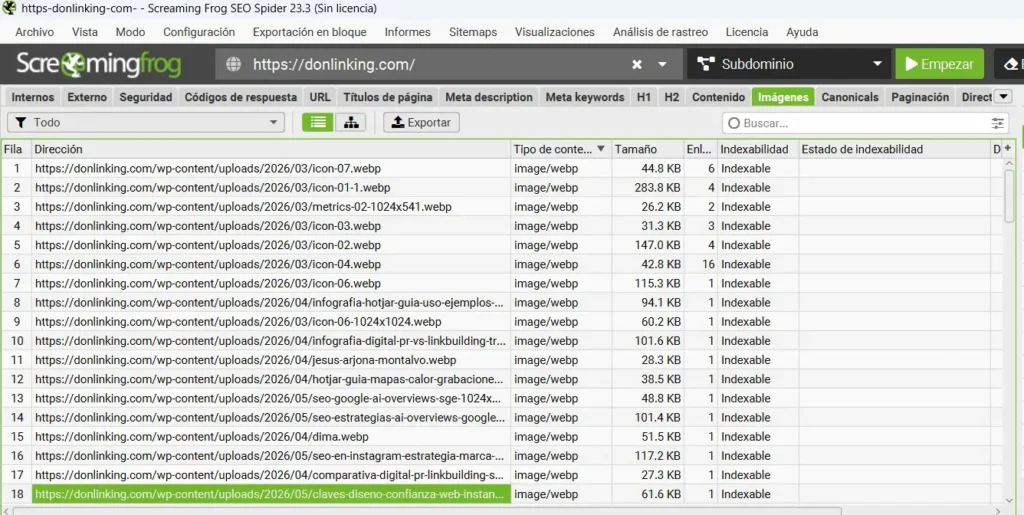
⚫ Images
- Missing Alt Text: imágenes sin atributo ALT. Google no puede «ver» imágenes, las entiende a través del ALT. Sin él, pierdes señal de relevancia y accesibilidad.
- Alt Text Over 100 Characters: ALTs demasiado largos que parecen spam de keywords.
- Over 100kb: imágenes pesadas que ralentizan la carga. Cualquier imagen por encima de 100kb debe comprimirse. Por encima de 500kb es un problema serio de rendimiento.
🟤 Directives
Aquí ves todas las directivas de indexación aplicadas en cada URL:
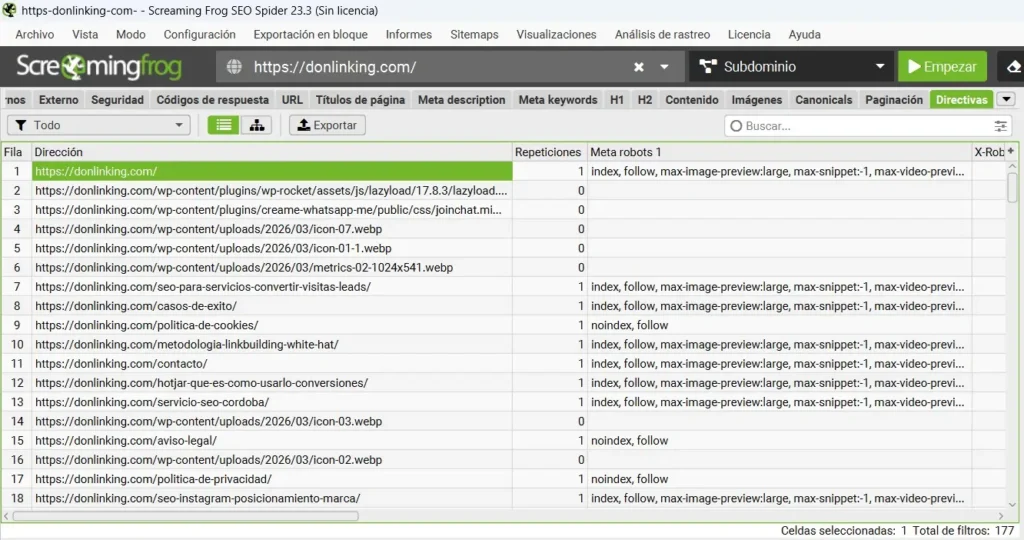
- Noindex: páginas que le dices a Google que no indexe. Verifica que sean las correctas. Es habitual encontrar páginas importantes marcadas con noindex por error.
- Nofollow: páginas o secciones donde bloqueas el paso de autoridad. Revisa que no estés bloqueando el flujo hacia páginas clave.
- Páginas bloqueadas en robots.txt: Screaming Frog puede mostrarte qué URLs están bloqueadas. Cruza con las que tienen backlinks o tráfico para detectar errores graves.
🟢 Sitemaps
Screaming Frog puede leer tu sitemap XML e identificar discrepancias:
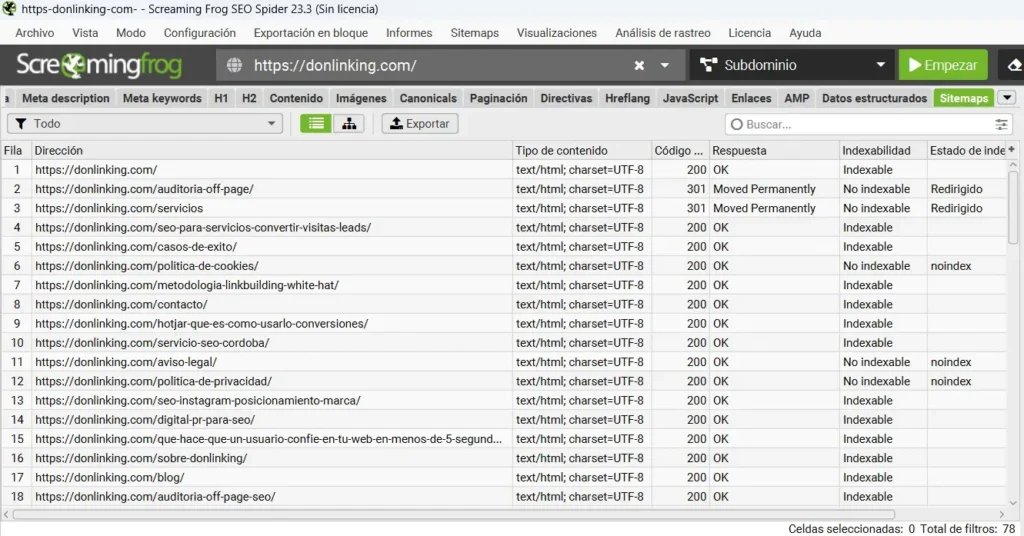
- URLs en sitemap que devuelven 404: páginas eliminadas que siguen declaradas en el sitemap.
- URLs en sitemap bloqueadas por robots.txt: contradicción directa: declaras la URL para que Google la rastree y al mismo tiempo la bloqueas.
- URLs no encontradas durante el rastreo: páginas en el sitemap a las que no se llega desde ningún enlace interno. Posibles páginas huérfanas.
Un sitemap limpio y actualizado facilita la indexación de tus páginas y reduce el tiempo que tarda Google en descubrir contenido nuevo.
🔗 Inlinks
Esta pestaña muestra, para cada URL, cuántos enlaces internos la apuntan y desde qué páginas. Es fundamental para entender cómo se distribuye la autoridad dentro del sitio.
Qué revisar:
- Páginas con 0 inlinks: páginas huérfanas. Google las encuentra con dificultad o no las encuentra.
- Anchor text interno: si todos los enlaces a una página usan el mismo anchor exacto, puede parecer forzado. Si usan anchors genéricos («haz clic aquí», «ver más»), pierdes señal de relevancia.
- Páginas con muchos inlinks vs pocas conversiones: puede indicar que la arquitectura de enlaces no está orientada al negocio.
El enlazado interno es uno de los mecanismos más eficaces para traspasar link juice entre páginas y reforzar las que más te interesa posicionar.
🚨 Problemas SEO que puedes detectar con Screaming Frog
Contenido duplicado
Páginas con títulos, H1 o contenido idéntico. En ecommerce es especialmente frecuente: productos con variantes (talla, color) que generan URLs diferentes con el mismo contenido. Screaming Frog los detecta comparando títulos, meta descriptions y en algunos casos el contenido near-duplicate.
URLs inútiles indexadas
Páginas de búsqueda interna, de parámetros de sesión, de filtros de facetas o páginas de error personalizadas que responden con 200 y están indexadas sin que sirvan para nada. Detectarlas y excluirlas del índice mejora la eficiencia del rastreo.
Páginas huérfanas
Páginas que existen pero a las que no apunta ningún enlace interno. Google las descubre solo si están en el sitemap o si tiene backlinks externos. Si no, pueden quedar fuera del radar durante meses. Filtra por Inlinks = 0 en la pestaña Internal para encontrarlas.
Problemas de rastreo
URLs con tiempos de respuesta muy altos, errores 5xx intermitentes o páginas que Google visita con mucha menos frecuencia de lo esperado. Para un análisis más profundo, combina Screaming Frog con el análisis de logs de Googlebot para ver exactamente cómo y cuándo rastrea Google tu sitio.
Canibalización técnica
Varias URLs que compiten por las mismas keywords porque tienen titles, H1 y contenido similares. Screaming Frog te muestra los títulos duplicados y los H1 repetidos; a partir de ahí puedes cruzar con datos de Search Console para confirmar si hay canibalización real. Aprende a detectar y corregir la canibalización SEO antes de que afecte al ranking de tus páginas principales.
Arquitectura deficiente
Páginas importantes a más de 4 clics de la home, secciones clave sin enlaces desde la navegación principal, o una distribución de autoridad interna que no favorece las páginas que generan negocio. Screaming Frog visualiza la profundidad de clic de cada URL y te permite detectar estos problemas de estructura.
📊 Cómo priorizar errores SEO encontrados
No todos los errores tienen el mismo impacto. Tras un rastreo, la lista puede ser larga y abrumadora. Esta es la jerarquía de priorización que aplican los SEOs profesionales:
Críticos (resolver en la primera semana):
- Páginas importantes con noindex activo por error
- Errores 5xx en URLs clave
- Canonical apuntando a URLs incorrectas en páginas con tráfico
- Páginas indexadas bloqueadas en robots.txt
Importantes (resolver en el primer mes):
- Cadenas de redirecciones
- Errores 404 internos
- Páginas sin title o con titles duplicados
- Imágenes sin ALT en páginas relevantes
- Páginas huérfanas con backlinks externos
Mejoras (planificar a medio plazo):
- Títulos y metas poco optimizados
- Click depth elevado en páginas secundarias
- Imágenes pesadas en páginas con tráfico moderado
- URLs con parámetros gestionadas pero no óptimas
Cómo conectar Screaming Frog a Search Console
1. Abre Screaming Frog y ve a: Configuration → API Access → Google Search Console
2. Haz clic en «Connect» Se abrirá el navegador para que inicies sesión con tu cuenta de Google.
3. Autoriza el acceso Acepta los permisos que pide Screaming Frog para leer datos de Search Console. Solo necesita permisos de lectura.
4. Selecciona la propiedad Elige la propiedad de Search Console que corresponde al sitio que vas a rastrear. Debe coincidir exactamente (con o sin www, http o https).
5. Lanza el rastreo normalmente Una vez conectado, al rastrear el sitio Screaming Frog pedirá datos a la API de Search Console automáticamente para cada URL.
6. Consulta los datos en la pestaña «Search Console» Verás columnas con impresiones, clics, CTR y posición media para cada URL rastreada.
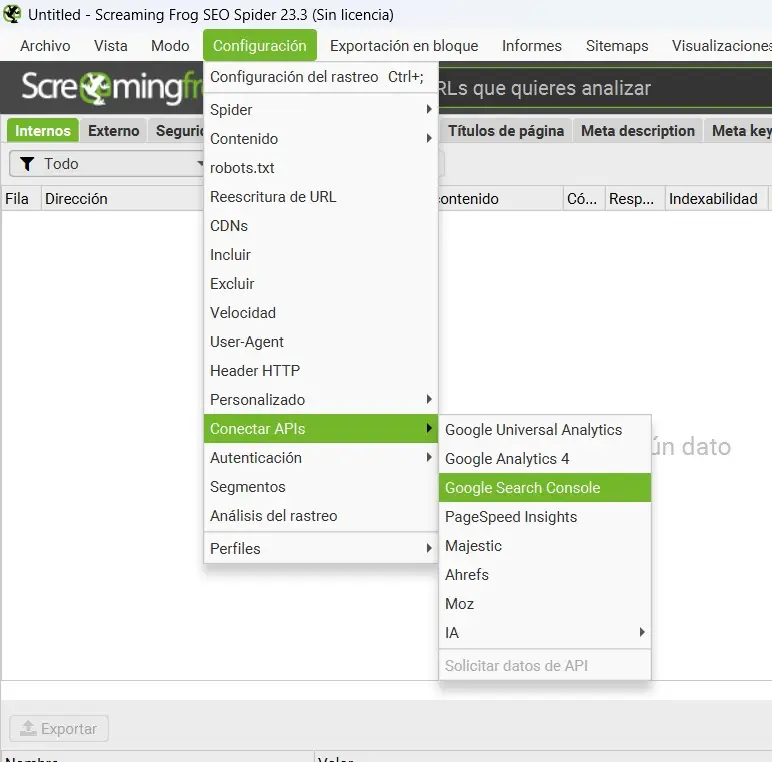
Conectando Screaming Frog con Google Search Console (via API) puedes cruzar datos de rastreo con datos reales de Google: qué páginas tiene indexadas, cuáles generan impresiones, cuáles tienen errores de cobertura. Esto permite identificar páginas que Google rastreó pero no indexó, o páginas con tráfico que tienen problemas técnicos que las frenan.
Cómo conectar Screaming Frog a Google Analytics 4
1. Abre Screaming Frog y ve a: Configuration → API Access → Google Analytics
2. Haz clic en «Connect» Se abre el navegador para autenticarte con tu cuenta de Google. Debe ser la misma cuenta que tiene acceso a la propiedad de GA4.
3. Autoriza los permisos Screaming Frog solicita acceso de lectura a Google Analytics. Acepta y vuelve a la herramienta.
4. Selecciona la propiedad de GA4 En el desplegable elige la propiedad correcta. Asegúrate de seleccionar una propiedad GA4 (las antiguas Universal Analytics ya no funcionan).
5. Configura las métricas que quieres importar Aquí puedes elegir qué datos traer para cada URL. Las más útiles son:
- Sessions → visitas totales por página
- Engaged Sessions → sesiones con interacción real
- Conversions → si tienes eventos de conversión configurados en GA4
- Average Engagement Time → tiempo medio de interacción
6. Define el rango de fechas Elige el período del que quieres traer datos. Lo más habitual es los últimos 3 o 6 meses para tener una muestra representativa sin que afecten estacionalidades puntuales.
7. Lanza el rastreo Al rastrear, Screaming Frog consulta la API de GA4 para cada URL y añade las métricas seleccionadas como columnas adicionales.
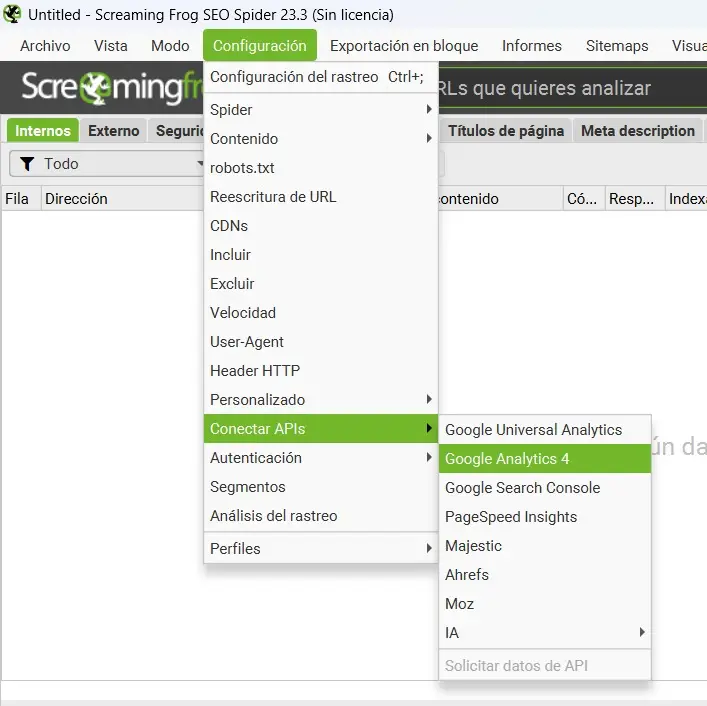
Search Console te dice cómo ve Google tus páginas. GA4 te dice cómo se comportan los usuarios reales en ellas. Al cruzar ambas fuentes con el rastreo de Screaming Frog, puedes tomar decisiones técnicas basadas en impacto de negocio real, no solo en severidad técnica.
Ejemplo práctico: Screaming Frog detecta 40 páginas con títulos duplicados. Sin GA4 no sabes por dónde empezar. Con GA4 conectado ves que 3 de esas páginas concentran el 80% del tráfico del sitio. Empiezas por ahí.
Qué mirar una vez conectado
- Páginas con muchas sesiones + errores técnicos: son las que más daño están recibiendo. Prioridad máxima.
- Páginas con 0 sesiones indexadas: están en Google pero nadie llega. Problema de posicionamiento o de demanda.
- Páginas con alto engagement + poco tráfico: contenido que funciona bien pero que no está bien posicionado. Candidatas a refuerzo de enlazado.
- Páginas con conversiones + problemas de velocidad: cualquier fricción técnica en estas URLs tiene impacto directo en negocio.
Requisito previo
Necesitas tener acceso de Lector como mínimo a la propiedad de GA4 en la cuenta de Google que usas para la conexión. Si la propiedad es de un cliente, tendrás que pedirle que añada tu cuenta con ese permiso desde Administración → Gestión de acceso en GA4.La integración con Google Analytics 4 añade datos de sesiones, usuarios y conversiones a cada URL rastreada. Así puedes priorizar las correcciones técnicas en función del impacto de negocio real: no es lo mismo un error en una página que genera 10 visitas al mes que en una que genera 5.000.
Ejemplo práctico: Screaming Frog detecta 40 páginas con títulos duplicados. Sin GA4 no sabes por dónde empezar. Con GA4 conectado ves que 3 de esas páginas concentran el 80% del tráfico del sitio. Empiezas por ahí.
Diferencia clave con Search Console
| Search Console | GA4 | |
|---|---|---|
| Qué mide | Visibilidad en Google | Comportamiento de usuario |
| Dato clave | Impresiones y posición | Sesiones y conversiones |
| Para qué sirve | Saber si Google ve la página | Saber si la página genera negocio |
Lo ideal es tener las dos conectadas a la vez para cruzar los tres niveles: rastreo técnico + visibilidad en Google + impacto en negocio.
Cómo conectar Screaming Frog a PageSpeed Insights
Screaming Frog puede lanzar automáticamente análisis de PageSpeed para cada URL rastreada y mostrar las Core Web Vitals directamente en la interfaz. Útil para detectar qué páginas específicas tienen problemas de rendimiento, en lugar de analizar solo la home.
1. Consigue una API Key de Google Ve a: console.developers.google.com
- Crea un proyecto nuevo o usa uno existente
- Ve a Biblioteca y busca PageSpeed Insights API
- Actívala
- Ve a Credenciales → Crear credencial → Clave de API
- Copia la clave generada
2. Abre Screaming Frog y ve a: Configuration → API Access → PageSpeed Insights
3. Pega tu API Key En el campo correspondiente pega la clave que copiaste en el paso anterior.
4. Selecciona el dispositivo Elige entre Desktop, Mobile o ambos. Lo más habitual es analizar Mobile primero, ya que Google usa el índice mobile-first.
5. Selecciona las métricas a importar Las más relevantes son:
- LCP (Largest Contentful Paint) → velocidad de carga del elemento principal
- CLS (Cumulative Layout Shift) → estabilidad visual
- INP (Interaction to Next Paint) → respuesta a interacciones
- Performance Score → puntuación global de 0 a 100
- FCP (First Contentful Paint) → tiempo hasta el primer contenido visible
6. Lanza el rastreo Screaming Frog consultará la API de PageSpeed para cada URL durante el rastreo. Ten en cuenta que esto ralentiza bastante el proceso, ya que cada URL requiere una llamada adicional a la API.
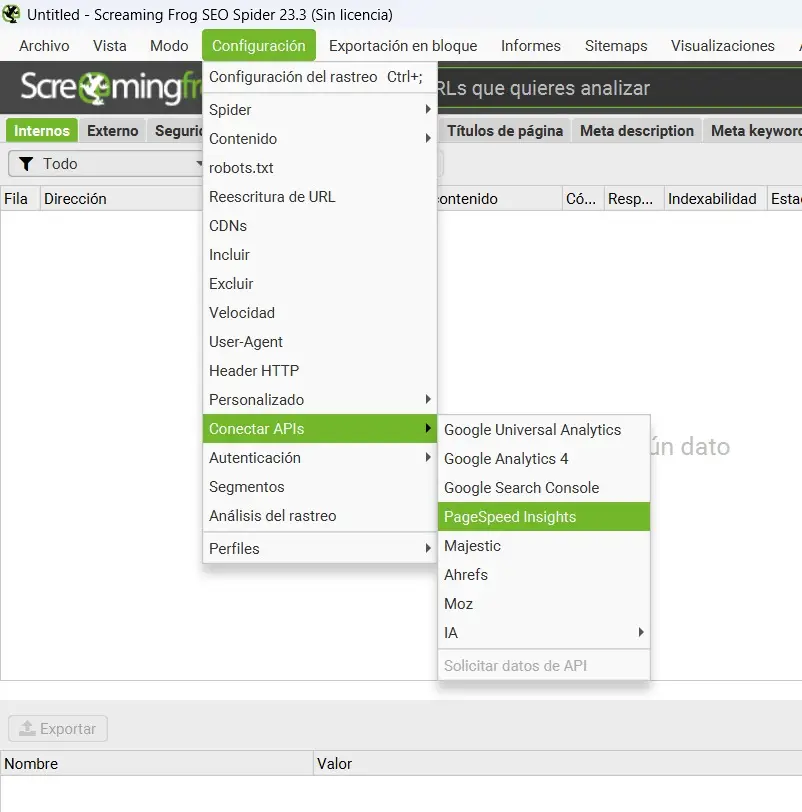
Qué mirar una vez conectado
- URLs con LCP superior a 2,5 segundos: suspenden el Core Web Vitals. Si son páginas con tráfico, es prioridad.
- URLs con CLS superior a 0,1: elementos que se mueven durante la carga. Muy habitual en páginas con banners o imágenes sin dimensiones definidas.
- URLs con Performance Score bajo en móvil pero alto en desktop: problema frecuente en webs con imágenes no optimizadas para pantallas pequeñas.
- Diferencia entre páginas clave y el resto: si la home pasa el CWV pero las fichas de producto o los artículos del blog no, el problema no es global sino de plantilla.
Limitación importante
La API gratuita de PageSpeed tiene un límite de 25.000 consultas al día, lo que en la práctica es más que suficiente para la mayoría de sitios. Sin embargo, si rastreas sitios muy grandes conviene segmentar el rastreo por secciones para no agotar la cuota y que el proceso no se eternice.
Comparativa de las tres integraciones
| Search Console | GA4 | PageSpeed | |
|---|---|---|---|
| Qué aporta | Visibilidad en Google | Impacto en negocio | Rendimiento técnico |
| Dato clave | Impresiones y posición | Sesiones y conversiones | Core Web Vitals |
| Requiere API Key | No | No | Sí (gratuita) |
| Ralentiza el rastreo | Poco | Poco | Bastante |
⚠️ Errores comunes usando Screaming Frog
Quedarse solo en la superficie
El error más frecuente es analizar únicamente los títulos y las metas. Es el uso más superficial de la herramienta y, además, el que menos valor aporta. Los problemas que realmente frenan el posicionamiento están en la indexabilidad, los canonicals y la arquitectura, no en si el título tiene 58 o 62 caracteres.
Ignorar la indexabilidad
Muchos SEOs exportan datos sin filtrar primero por páginas indexables. Analizar URLs que Google no va a indexar de todas formas es, en la práctica, perder el tiempo. Por eso, lo primero antes de cualquier revisión es aplicar el filtro de indexabilidad y trabajar solo con lo que importa.
Pasar por alto la profundidad de clics
Una página a 7 clics de la home tiene pocas probabilidades de posicionar bien, aunque el contenido sea excelente. Sin embargo, este dato pasa desapercibido cuando el análisis se centra demasiado en los metadatos y no en la arquitectura real del sitio.
Mezclar canonical y noindex
Son directivas distintas con propósitos diferentes: el canonical le indica a Google cuál es la versión preferida de una URL, mientras que el noindex le dice que no la incluya en el índice. Confundirlas o usarlas de forma incorrecta genera problemas técnicos difíciles de detectar a simple vista.
Confundir rastreo con indexación
Que Screaming Frog encuentre una página no implica que Google la tenga indexada. Del mismo modo, que esté indexada no garantiza que posicione. En realidad, son tres fases con variables independientes: rastreo → indexación → posicionamiento. Entender esta distinción es clave para interpretar correctamente los datos del rastreo.
📈 Qué haría un SEO profesional tras el rastreo
Un SEO con experiencia no empieza a corregir errores aleatoriamente. El proceso tras un rastreo completo sigue esta lógica:
1. Filtrar por indexabilidad. Trabajar solo con las URLs que Google puede indexar. Las demás son contexto, no prioridad.
2. Identificar los errores críticos. Buscar primero noindex incorrectos, errores de servidor y canonicals rotos en páginas con tráfico o backlinks.
3. Cruzar con Search Console. Ver qué dice Google sobre las páginas que Screaming Frog detecta como problemáticas. A veces Google ya lo sabe; otras veces no.
4. Generar un plan de correcciones priorizado. Documento con errores, impacto estimado, responsable y fecha límite. Sin esto, la auditoría se queda en datos sin acción.
5. Limpiar URLs innecesarias. Noindexar o canonicalizar páginas que no aportan valor al índice. Una web más limpia se rastrea mejor y posiciona más fácil.
6. Reforzar el enlazado interno. Tras identificar páginas huérfanas y páginas con pocos inlinks, redistribuir el enlazado para que la autoridad fluya hacia donde más importa.
7. Acompañar la parte técnica con la parte off-page. La auditoría técnica es solo una parte del trabajo. Una web técnicamente sana necesita también un perfil de enlaces sólido para competir. Puedes ver cómo se complementa con la auditoría off-page para tener una visión completa del estado SEO del sitio.
Un proyecto de desarrollo web bien estructurado desde el inicio puede evitar la mayoría de los errores técnicos que luego requieren horas de auditoría para corregir. Si el sitio arrastra problemas de arquitectura profundos, a veces la solución más eficiente es un proyecto de desarrollo web orientado a SEO desde la base.
Preguntas Frecuentes de Screaming Frog
¿Screaming Frog sirve para auditar tiendas online grandes?
Sí, y es especialmente útil en ecommerce porque estas webs suelen generar miles de URLs de variantes, filtros y paginación que pueden saturar el índice de Google. Screaming Frog permite detectar qué URLs están indexadas innecesariamente y cuáles tienen contenido duplicado por variantes de producto. Para ecommerce grandes, combínalo con el análisis de logs para entender cómo distribuye Google el presupuesto de rastreo entre tus secciones.
¿Cuántas URLs puede rastrear Screaming Frog?
La versión gratuita tiene un límite de 500 URLs por rastreo. La versión de pago no tiene límite práctico: puede rastrear sitios con millones de URLs, aunque en webs muy grandes necesitarás configurar correctamente la memoria asignada a Java y segmentar el rastreo por secciones para manejarlo de forma eficiente.
¿La versión gratuita es suficiente para empezar?
Depende del tamaño del sitio. Para webs de menos de 500 URLs —blogs, webs corporativas pequeñas o landings— la versión gratuita cubre la mayoría de los análisis necesarios. Para sitios más grandes o si necesitas integración con Search Console o GA4, la versión de pago es imprescindible.
¿Puede Google bloquear el rastreo de Screaming Frog?
Técnicamente sí. Si el servidor detecta un volumen inusual de peticiones desde una misma IP, puede bloquearla temporalmente. Para evitarlo, reduce la velocidad de rastreo en la configuración. También puedes cambiar el User-Agent a Googlebot, aunque algunos servidores responden de forma diferente a bots conocidos. En servidores bien configurados, un rastreo a velocidad moderada no genera ningún problema.
¿Qué diferencia hay entre rastreo e indexación?
El rastreo es el proceso por el que Googlebot (o Screaming Frog) visita una URL y lee su contenido. La indexación es la decisión de Google de incluir esa URL en su base de datos para mostrarla en resultados. Que una página sea rastreada no garantiza que sea indexada: Google puede rastrearla y descartarla por thin content, contenido duplicado o señales de baja calidad. Y que esté indexada no significa que posicione bien. Son tres pasos con variables independientes.