
Google Search Console te muestra qué páginas están indexadas y cuáles tienen problemas. Pero no te dice qué hace Googlebot exactamente cuando visita tu web, qué URLs prioriza, cuáles ignora ni con qué frecuencia vuelve. Para eso están los logs del servidor: el registro más honesto de lo que Google hace realmente en tu sitio.
En este artículo te explicamos qué son los logs, qué puedes descubrir con ellos y cómo usarlos para mejorar el rastreo de tu web con ejemplos reales en cada sección.
Cuando llegan clientes a nuestra agencia de enlaces para posicionar webs, el análisis de logs forma parte del diagnóstico previo en proyectos con problemas de indexación o rastreo. Es una de las pocas fuentes de datos que no interpreta ni estima: registra exactamente cada visita de Googlebot, con hora, URL, código de respuesta y tiempo de carga.
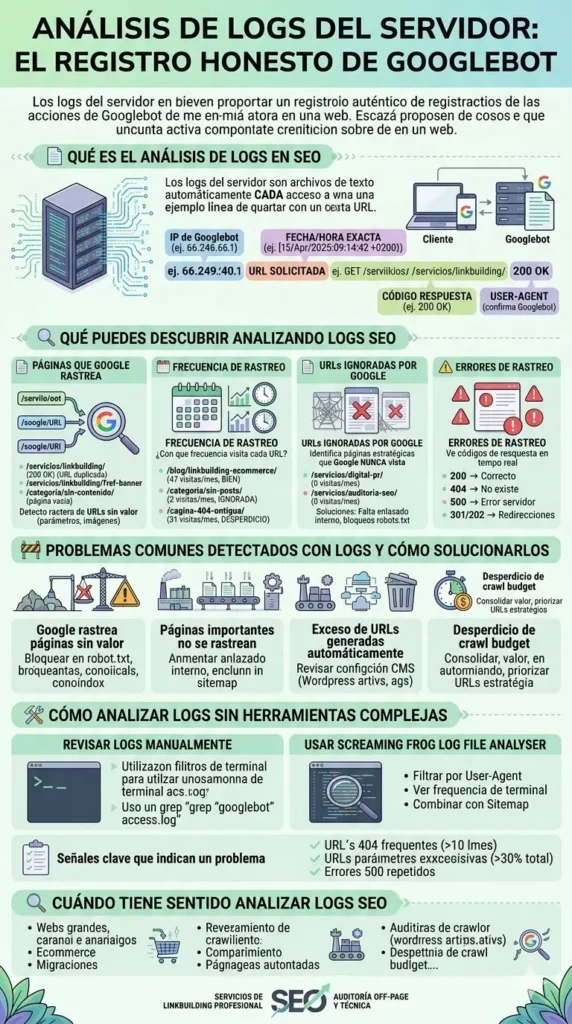
📋 Qué es el análisis de logs en SEO
Qué son los logs del servidor
Los logs del servidor son archivos de texto que genera automáticamente el servidor web cada vez que alguien (o algo) accede a una URL. Cada línea del archivo es una solicitud: quién la hizo, qué URL pidió, cuándo, qué código de respuesta recibió el servidor y cuánto tardó en responder.
Cuando Googlebot visita tu web, deja exactamente la misma huella en el log que cualquier visitante, solo que con un user-agent identificable. Eso te permite filtrar sus visitas y analizar su comportamiento de forma aislada.
Qué información contienen
Una línea típica de log en formato Apache o Nginx contiene estos campos:
📌 Ejemplo: línea real de log de servidor
66.249.66.1 – – [15/Apr/2025:09:14:32 +0200] «GET /servicios/linkbuilding/ HTTP/1.1» 200 4521 «-» «Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)»
Desglosado: 66.249.66.1 es la IP de Googlebot. [15/Apr/2025:09:14:32] es la fecha y hora exacta. «GET /servicios/linkbuilding/» es la URL solicitada. 200 es el código de respuesta (OK). Y el user-agent confirma que es Googlebot.
Por qué son importantes para el SEO técnico
Los logs revelan lo que ninguna otra herramienta puede darte con tanta precisión. Google Search Console muestra problemas de cobertura con retraso y datos agregados. Los logs muestran el rastreo en tiempo real, URL por URL. Eso permite detectar páginas que Google visita demasiado, páginas que nunca visita y errores que se producen en el momento exacto del rastreo.
Esta información es especialmente crítica cuando hay problemas de indexación lenta o páginas que no aparecen en Google: los logs son el primer lugar donde buscar la causa real.
🔍 Qué puedes descubrir analizando logs SEO
Qué páginas rastrea Googlebot
Filtrando las líneas del log por el user-agent de Googlebot, puedes ver exactamente qué URLs ha visitado y cuántas veces. Muchas veces el resultado sorprende: Googlebot dedica tiempo a URLs de parámetros, páginas de filtros o archivos de imágenes que no tienen ningún valor SEO.
📌 Ejemplo: URLs rastreadas por Googlebot en una web de servicios
/servicios/linkbuilding/ → 200 OK /servicios/linkbuilding/?ref=banner → 200 OK (duplicada) /categoria/sin-contenido/ → 200 OK (página vacía) /images/logo.png → 200 OK (recurso estático)
En este ejemplo, Googlebot está rastreando una URL duplicada por parámetro y una imagen. Ese esfuerzo podría dedicarse a páginas que sí importan. Este problema conecta directamente con la gestión del crawl budget y su impacto en el rastreo.
Frecuencia de rastreo
Los logs permiten ver con qué frecuencia visita Googlebot cada URL. Una página importante que solo recibe una visita al mes de Googlebot está siendo infravalorada. Una página sin valor que recibe visitas diarias está desperdiciando presupuesto de rastreo.
📌 Ejemplo: patrón de frecuencia de rastreo
/blog/linkbuilding-ecommerce/ → 47 visitas en abril (bien) /categoria/sin-posts/ → 2 visitas en abril (ignorada) /pagina-404-antigua/ → 31 visitas en abril (problema)
La página con 404 que recibe 31 visitas al mes es un problema doble: consume crawl budget y transmite señales negativas. Probablemente tiene backlinks que apuntan a ella y que deberían redirigirse. Aquí es donde el proceso de link reclamation cobra sentido: recuperar esos enlaces redirigiendo a la URL correcta.
URLs ignoradas por Google
Tan importante como saber qué rastrea Google es saber qué no rastrea. Si una página estratégica no aparece en los logs, Google no la está visitando. Eso puede deberse a falta de enlazado interno, a que está bloqueada en robots.txt o simplemente a que no recibe suficientes señales de autoridad.
📌 Ejemplo: página prioritaria sin visitas de Googlebot
/servicios/digital-pr/ → 0 visitas en los últimos 30 días /servicios/auditoria-seo/ → 0 visitas en los últimos 30 días
Si estas páginas de servicio no aparecen en los logs, hay un problema estructural. O no tienen enlaces internos que las conecten con el resto de la web, o la autoridad no está fluyendo correctamente hacia ellas.
Errores de rastreo
Los logs muestran el código de respuesta HTTP de cada URL. Un 200 significa que todo fue bien. Un 404 indica que la página no existe. Un 500 es un error del servidor. Un 301 es una redirección. Ver estos códigos en masa permite identificar patrones de error que en Search Console aparecen con días de retraso.
📌 Ejemplo: códigos de respuesta en logs
200 → /servicios/linkbuilding/ (correcto) 404 → /articulo-borrado/ (página eliminada sin redirección) 500 → /categoria/proyectos/ (error de servidor) 301 → /blog/ → /blog/articulos/ (redirección correcta) 302 → /oferta-temporal/ (redirección temporal, revisar)
🤖 Cómo ver el comportamiento de Googlebot en tu web
Identificar visitas de Googlebot
Para filtrar las líneas del log que corresponden a Googlebot, busca el user-agent «Googlebot». En la práctica, hay varios tipos de Googlebot: el de búsqueda web, el de imágenes, el de noticias y el de vídeo. El más relevante para SEO es «Googlebot/2.1».
📌 Ejemplo: user-agent de Googlebot en el log
User-agent Googlebot web: «Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)» User-agent Googlebot mobile: «Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) … (compatible; Googlebot/2.1; +http://www.google.com/bot.html)»
Verificar que la IP de Googlebot es legítima es importante. Existen bots que se hacen pasar por Googlebot usando el mismo user-agent pero con IPs que no pertenecen a Google. Puedes verificar la autenticidad haciendo una búsqueda inversa de DNS de la IP.
Analizar patrones de rastreo
Una vez filtradas las visitas de Googlebot, el análisis de patrones revela cómo estructura Google su exploración de tu web. Lo habitual es que Googlebot empiece por las páginas más enlazadas internamente y vaya descendiendo en profundidad.
📌 Ejemplo: patrón de rastreo en una web de servicios
09:14:32 → / 09:14:35 → /servicios/ 09:14:38 → /servicios/linkbuilding/ 09:14:42 → /blog/ 09:14:55 → /blog/como-hacer-linkbuilding/ 09:15:10 → /contacto/
Este patrón es saludable: Googlebot sigue la jerarquía natural de la web. Si en cambio empieza por páginas de baja prioridad o se queda atascado en URLs de parámetros, hay un problema de arquitectura que resolver. Entender bien la estructura de URLs y redirecciones es parte de la solución.
Detectar páginas importantes vs. ignoradas
Compara el número de visitas de Googlebot por tipo de página. Las páginas que deberían tener más rastreo (servicios, categorías principales, artículos estratégicos) deberían aparecer con más frecuencia que las páginas secundarias.
📌 Ejemplo: comparativa de rastreo por tipo de página
Páginas de servicio: 12 visitas/mes de media Artículos de blog estratégicos: 8 visitas/mes de media Páginas de archivo de WordPress: 34 visitas/mes de media URLs con parámetros: 67 visitas/mes de media
En este ejemplo hay un problema claro: las páginas sin valor (archivos y parámetros) reciben más atención de Googlebot que las páginas estratégicas. Eso indica que la arquitectura no está distribuyendo bien las señales de prioridad.
🚧 Problemas comunes detectados con logs y cómo solucionarlos
Google rastrea páginas sin valor
⚠️ Problema: Googlebot dedica visitas a páginas de parámetros, archivos de WordPress, filtros de ecommerce o páginas de paginación antiguas que no aportan valor SEO.
✅ Solución: Bloquear esas URLs en robots.txt (si no necesitan ser rastreadas), añadir noindex donde corresponda o consolidarlas con canonical hacia la URL principal. El objetivo es que Googlebot dedique su presupuesto de rastreo a las páginas que importan.
📌 Ejemplo: bloqueo en robots.txt
User-agent: * Disallow: /*?ref= Disallow: /*?sort= Disallow: /author/ Disallow: /date/
Páginas importantes no se rastrean
⚠️ Problema: Páginas de servicio o artículos estratégicos no aparecen en los logs o aparecen con frecuencia muy baja, lo que indica que Googlebot no las está visitando con regularidad.
✅ Solución: Aumentar el enlazado interno hacia esas páginas desde URLs con más autoridad, incluirlas en el sitemap y asegurarse de que no están bloqueadas por robots.txt ni tienen noindex activo.
📌 Ejemplo: diagnóstico de página ignorada
URL: /servicios/auditoria-seo/ Visitas Googlebot últimos 30 días: 0 Enlaces internos apuntando a ella: 1 (solo desde el menú) Posición en el sitemap: no incluida Diagnóstico: subenlazada y fuera del sitemap
Exceso de URLs generadas automáticamente
⚠️ Problema: El CMS genera automáticamente URLs de archivos por fecha, autor, etiquetas o combinaciones de filtros, multiplicando el número de páginas rastreables sin valor añadido.
✅ Solución: Revisar la configuración del CMS y desactivar o poner en noindex las URLs generadas automáticamente que no tienen contenido diferenciado. En WordPress esto se gestiona desde Yoast SEO o Rank Math.
📌 Ejemplo: URLs automáticas problemáticas en WordPress
/author/admin/ → archivos de autor (sin valor) /tag/seo/ → página de etiqueta (duplicada con categoría) /2023/04/15/ → archivo de fecha (nunca debería indexarse) /?s=linkbuilding → resultado de búsqueda interna (siempre noindex)
Desperdicio de crawl budget
⚠️ Problema: Googlebot gasta la mayor parte de su presupuesto de rastreo en páginas de baja prioridad, dejando páginas estratégicas con frecuencia de rastreo insuficiente.
✅ Solución: Consolidar las páginas sin valor, mejorar el enlazado interno hacia las páginas prioritarias y asegurarse de que el sitemap solo incluye URLs que merecen ser rastreadas e indexadas.
El crawl budget no es infinito. En webs con miles de URLs, la gestión de qué páginas reciben atención de Googlebot es tan importante como el contenido de esas páginas. Una web con problemas de duplicidad técnica es especialmente propensa a desperdiciar crawl budget en versiones duplicadas de la misma página.
🛠️ Cómo analizar logs sin herramientas complejas
Revisar logs manualmente
Para webs pequeñas o como primer diagnóstico, puedes revisar los logs directamente. Accede a los archivos de log desde el panel de hosting (generalmente en la sección «Logs» o «Estadísticas») y descarga el archivo de acceso (access.log).
Abre el archivo con un editor de texto y busca el término «Googlebot». Cada línea que lo contenga es una visita del rastreador. Si el volumen es manejable (menos de 10.000 líneas), puedes hacer el análisis directamente.
📌 Ejemplo: filtro manual en terminal (Linux/Mac)
grep «Googlebot» access.log | grep » 404 » | sort | uniq -c | sort -rn | head -20
Este comando filtra todas las visitas de Googlebot que devolvieron error 404, las cuenta por URL y muestra las 20 más frecuentes. Es el punto de partida más rápido para identificar problemas críticos.
Usar Screaming Frog Log File Analyser
Para volúmenes mayores, Screaming Frog SEO Spider es la herramienta más accesible. Tiene una versión gratuita que permite analizar hasta 1.000 URLs y una de pago sin límite. Simplemente importas el archivo de log y la herramienta filtra automáticamente las visitas de Googlebot, las organiza por URL, código de respuesta y frecuencia, y permite exportar los resultados para análisis posterior.
La vista más útil es la de «Crawl Frequency»: muestra cuántas veces ha visitado Googlebot cada URL en el período analizado. Combinado con la exportación del sitemap y los datos de Search Console, permite cruzar qué páginas están en el sitemap, cuáles rastrea Google y cuáles tiene indexadas.
Qué patrones identificar
- URLs con código 404 que reciben visitas frecuentes de Googlebot → tienen backlinks o enlaces internos que apuntan a ellas.
- URLs de parámetros con muchas visitas → problema de control de parámetros.
- Páginas estratégicas con 0 o 1 visita al mes → subenlazadas o bloqueadas.
- Picos de rastreo en fechas concretas → Google ha detectado cambios importantes o ha seguido un enlace externo nuevo.
Señales clave que indican un problema
📌 Ejemplo: señales de alerta en los logs
URLs con 404 rastreadas más de 10 veces/mes → backlinks rotos o enlaces internos rotos URLs con parámetros: más del 30% del total rastreado → control de parámetros urgente Páginas de servicio: menos de 5 visitas/mes → subenlazadas Errores 500 repetidos → problema técnico del servidor
📐 Cuándo tiene sentido analizar logs SEO
El análisis de logs no es necesario en todos los proyectos ni en todo momento. Tiene más sentido en estos contextos:
- 🏗️ Webs grandes (más de 1.000 URLs): donde el control manual de qué rastrea Google es imposible sin datos de logs.
- 🛒 Ecommerce con filtros y facetado: donde la generación automática de URLs puede multiplicar exponencialmente el número de páginas rastreables. El linkbuilding para ecommerce pierde eficacia si la autoridad se reparte entre cientos de URLs de filtros duplicadas.
- 🔍 Proyectos con problemas de indexación: cuando páginas que deberían estar indexadas no aparecen en Google y Search Console no da una causa clara.
- 🔄 Tras una migración web: para verificar que las redirecciones funcionan correctamente y Googlebot está siguiendo los nuevos destinos.
- 📉 Tras una caída de tráfico: para descartar problemas de rastreo como causa de la pérdida de posiciones.
🔗 Relación entre logs, rastreo e indexación
El rastreo y la indexación son pasos distintos del proceso de Google. Que Googlebot rastree una página no garantiza que la indexe. Pero si no la rastrea, definitivamente no la indexa.
El análisis de logs permite identificar el primer punto de fallo en esa cadena: si la página no aparece en los logs, el problema está en el rastreo (enlazado, bloqueos, arquitectura). Si aparece en los logs pero no en el índice, el problema está en la calidad del contenido o en señales como el canonical o el noindex.
📌 Ejemplo: cadena de diagnóstico con logs
Situación: página /servicios/linkbuilding-local/ no aparece en Google Paso 1 → revisar logs: ¿aparece rastreada? → No aparece en los logs → problema de rastreo → Causa probable: sin enlaces internos o bloqueada Si aparece en los logs: Paso 2 → revisar código de respuesta: → 200 OK pero no indexada → revisar noindex, canonical y calidad de contenido → 404 → crear o redirigir → 301 → la redirección consume rastreo; verificar destino
Este flujo de diagnóstico es el que aplicamos en una auditoría off-page y técnica completa: primero identificar si el problema es de rastreo, de indexación o de autoridad, y actuar en el punto correcto.
✅ Para concluir: el análisis de logs te muestra lo que Google hace, no lo que crees que hace
La mayoría de decisiones SEO se toman basándose en inferencias: asumimos que Google rastrea lo que debería rastrear, indexa lo que queremos que indexe y valora lo que hemos optimizado. Los logs eliminan esa incertidumbre. Te muestran la realidad tal como es, sin filtros ni retrasos.
Identificar que Googlebot dedica el 60 % de sus visitas a URLs sin valor, o que una página estratégica lleva tres meses sin ser rastreada, son hallazgos que no aparecen en ningún otro informe. Y son exactamente el tipo de problemas que, una vez corregidos, desbloquean mejoras de posicionamiento que de otra forma quedan ocultas.
Si quieres que el trabajo off-page que haces tenga el máximo impacto, la base técnica tiene que estar en orden. Puedes ver cómo trabajamos la estrategia completa, desde la arquitectura hasta la construcción de autoridad, en los servicios de linkbuilding profesional o revisar nuestra metodología de trabajo de linkbuilding con criterio técnico.
Preguntas frecuentes sobre análisis de logs SEO
¿Qué es un log en SEO?
Un log en SEO es el registro que genera el servidor web de cada solicitud de acceso a una URL. Para el SEO, lo relevante es filtrar las solicitudes que provienen de Googlebot, lo que permite ver exactamente qué páginas rastrea, con qué frecuencia y qué código de respuesta reciben. Es la fuente de datos más precisa sobre el comportamiento real del rastreador de Google.
¿Cómo saber qué páginas rastrea Google?
Hay dos formas principales. La primera es revisar los logs del servidor filtrando por el user-agent de Googlebot. La segunda es usar el informe de Cobertura de Google Search Console, que muestra qué URLs ha procesado Google aunque con menos detalle y con cierto retraso. Para proyectos grandes o con problemas específicos, los logs son siempre más precisos.
¿Googlebot visita todas las páginas de una web?
No. Googlebot prioriza las páginas según su autoridad, la frecuencia de actualización del contenido y las señales de enlazado interno y externo. Páginas con pocos enlaces internos, sin backlinks externos y sin actualizaciones recientes pueden no recibir visitas de Googlebot durante meses. Mejorar el enlazado hacia esas páginas y conseguir backlinks editoriales relevantes aumenta la probabilidad de que sean rastreadas con más frecuencia.
¿Necesito herramientas de pago para analizar logs?
No necesariamente. Para webs pequeñas puedes revisar los logs manualmente con un editor de texto o con comandos básicos de terminal. Screaming Frog Log File Analyser tiene una versión gratuita hasta 1.000 URLs que es suficiente para la mayoría de proyectos medianos. Las herramientas de pago como SEOlyzer o Botify tienen más capacidad pero no son imprescindibles para empezar.
¿El análisis de logs mejora el SEO directamente?
No mejora el SEO por sí solo, pero permite identificar problemas que sí tienen impacto directo en el posicionamiento: páginas no rastreadas, crawl budget desperdiciado, errores 404 con backlinks o redirecciones mal configuradas. Al corregir esos problemas con datos reales en lugar de suposiciones, las mejoras de posicionamiento son más predecibles y sostenibles.