
La duplicidad técnica en SEO es uno de los problemas más frecuentes y menos visibles de un proyecto web. No siempre está en el contenido: muchas veces está en las URLs. Google puede estar viendo varias versiones de una misma página y repartiendo la relevancia entre ellas sin que lo notes en el día a día.
En nuestra agencia de linkbuilding y SEO técnico detectamos constantemente en las auditorías de webs que ejecutamos que no terminan de posicionar a pesar de tener buen contenido y una estrategia activa. El problema no es lo que se publica: es la estructura desde la que se publica. En este artículo te explicamos cómo identificar y solucionar sin necesidad de herramientas que cuestan un pastizal.
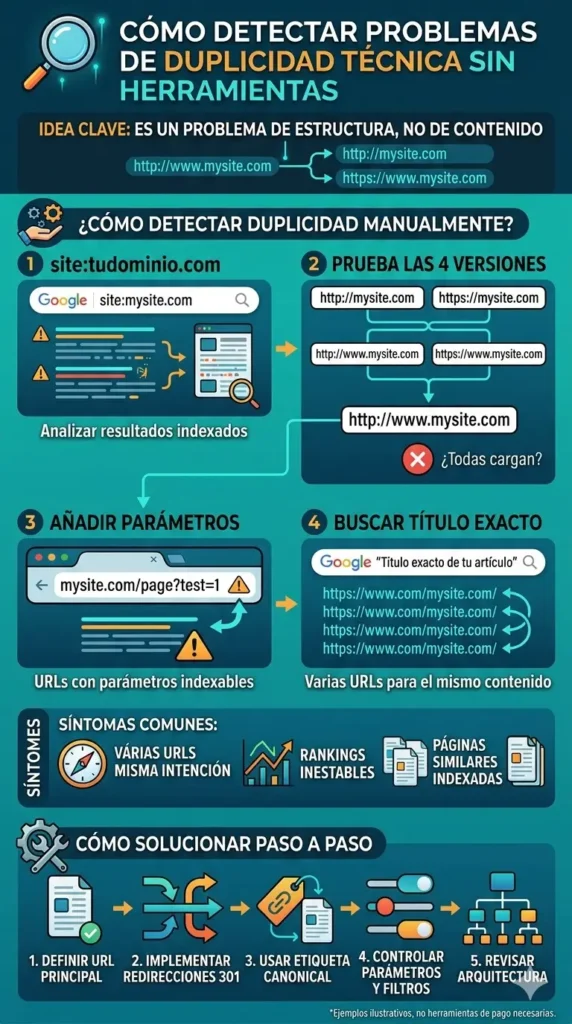
💡 Idea clave: la duplicidad técnica no es un problema de contenido, es un problema de estructura. Cuando varias URLs representan lo mismo, Google reparte señales y el SEO pierde fuerza.
🔍 Qué es la duplicidad técnica en SEO (más allá del contenido duplicado)
Diferencia entre duplicidad de contenido y duplicidad técnica
La duplicidad de contenido ocurre cuando el mismo texto aparece en varias páginas distintas. La duplicidad técnica es diferente: ocurre cuando una misma página es accesible desde varias URLs distintas sin que el contenido cambie. No es un problema editorial, es un problema de arquitectura.
Un ejemplo claro: si tu web carga correctamente tanto en «https://tudominio.com» como en «http://www.tudominio.com», tienes cuatro versiones del mismo sitio accesibles simultáneamente. El contenido es idéntico, pero Google las interpreta como páginas diferentes y tiene que decidir cuál posicionar.
Por qué Google indexa múltiples versiones de una misma página
Google rastrea las URLs que encuentra, no las que tú quieres que rastree. Si no hay redirecciones claras, etiquetas canonical bien configuradas o una estructura de URLs coherente, el rastreador accede a todas las versiones que encuentra y las trata como páginas independientes. El resultado es que la autoridad y la relevancia que deberían concentrarse en una sola URL se reparten entre varias, debilitando el posicionamiento de todas.
Este problema afecta directamente a la autoridad de tu web porque las señales de los backlinks también se dispersan entre versiones. Un enlace que apunta a la versión HTTP no suma lo mismo que si la web tuviera una única versión consolidada en HTTPS.
⚙️ Tipos de duplicidad técnica más comunes
URLs con y sin www
⚠️ Problema: Tu web carga con y sin «www», generando dos versiones del mismo sitio accesibles simultáneamente.
👉 Solución: redirigir una versión a la otra con redirección 301 y mantener coherencia en todos los enlaces internos y externos. La versión elegida debe ser siempre la misma en el sitemap, en el canonical y en los backlinks.
HTTP vs HTTPS
⚠️ Problema: El sitio es accesible en ambas versiones, HTTP y HTTPS, sin redirigir automáticamente a la versión segura.
👉 Solución: forzar HTTPS en el servidor y redirigir todo el tráfico HTTP a la versión segura. Es el mínimo técnico exigible en cualquier web en 2025 y afecta directamente a la confianza que Google deposita en el dominio.
Parámetros en URLs (?utm, filtros, etc.)
⚠️ Problema: URLs con parámetros como «?utm_source=», «?filter=» o «?sort=» generan múltiples versiones de la misma página que Google puede indexar por separado.
👉 Solución: definir una URL principal para cada página y usar la etiqueta canonical apuntando a esa versión. Para parámetros de seguimiento como UTM, asegurarse de que no son indexables. Este tipo de duplicidad también afecta al crawl budget en webs grandes.
Entender cómo gestiona Google el crawl budget y su impacto en el SEO es clave para priorizar qué URLs deben rastrearse y cuáles deben bloquearse o consolidarse.
Paginaciones mal gestionadas
⚠️ Problema: Varias páginas de paginación con contenido muy similar compiten entre sí y diluyen la relevancia del contenido principal.
👉 Solución: estructurar correctamente la paginación, asegurarse de que la página principal acumula la mayor parte de la autoridad y usar canonical cuando sea necesario para señalar la versión prioritaria.
Filtros en ecommerce o webs grandes
⚠️ Problema: Cada combinación de filtros genera una URL distinta: color, talla, precio, orden… El número de URLs puede multiplicarse de forma exponencial.
👉 Solución: limitar la indexación de las URLs de filtros usando noindex o canonical hacia la categoría principal. Solo deben indexarse las combinaciones que tienen volumen de búsqueda real y contenido diferenciado.
Este problema es especialmente relevante en proyectos de con un ecommerce donde la estructura de URLs del catálogo puede generar cientos de páginas duplicadas que drenan el presupuesto de rastreo y diluyen la autoridad de las categorías principales.
Archivos de fecha, autor y categorías en CMS como WordPress
⚠️ Problema: WordPress genera automáticamente URLs de archivo por fecha, autor y categorías que replican listados de contenido ya existente, creando duplicidad de contexto sin valor añadido.
👉 Solución: revisar la configuración del CMS y desactivar o poner en noindex los archivos que no aporten contenido diferenciado. Las categorías que sí merecen posicionar deben tener contenido propio, algo que desarrollamos en profundidad en la guía sobre
Las categorías SEO bien estructuradas no solo evitan duplicidad: también consolidan la autoridad temática y mejoran la distribución interna de señales.
🕵️ Cómo detectar duplicidad técnica sin herramientas
Buscar en Google con site:
Escribe en Google: site:tudominio.com y analiza los resultados. Si aparecen URLs con patrones extraños, parámetros, versiones de paginación o páginas de archivo que no debería estar indexadas, tienes un problema de duplicidad.
⚠️ Problema: Aparecen URLs duplicadas, con parámetros o sin sentido editorial entre los resultados indexados.
👉 Solución: identificar los patrones de URL problemáticos, su origen (CMS, filtros, parámetros) y decidir si se consolidan con canonical, se redirigen o se excluyen de la indexación.
Buscar versiones duplicadas manualmente
Prueba acceder a tu web en estas cuatro combinaciones y comprueba si todas cargan sin redirigir:
- http://tudominio.com
- https://tudominio.com
- http://www.tudominio.com
- https://www.tudominio.com
⚠️ Problema: Todas las versiones cargan sin redirigir automáticamente a una sola, lo que genera duplicidad estructural del sitio completo.
👉 Solución: unificar mediante redirecciones 301 hacia la versión principal. Las redirecciones bien configuradas son la forma más directa de consolidar autoridad entre versiones duplicadas.
Entender la diferencia entre tipos de redirección es fundamental antes de implementar cualquier cambio. Nuestra guía sobre redirecciones 301 y 302 en SEO explica cuándo usar cada una y cómo afectan al traspaso de autoridad entre URLs.
Analizar la URL cambiando parámetros manualmente
Añade manualmente un parámetro a una URL de tu web: por ejemplo, tudominio.com/pagina/?test=1. Si la página carga correctamente sin ningún control, Google puede estar indexando esa versión como una página independiente.
⚠️ Problema: La URL con parámetro carga sin redirección ni error, lo que indica que puede ser rastreada e indexada como página separada.
👉 Solución: definir la versión principal de cada página mediante canonical y controlar qué parámetros pueden generar versiones indexables.
Buscar títulos exactos en Google
Busca en Google el título exacto de uno de tus artículos entre comillas: «Título exacto de tu artículo». Si aparecen varias URLs con el mismo contenido en los resultados, tienes duplicidad activa que Google ya ha detectado.
⚠️ Problema: Varias URLs muestran el mismo contenido en los resultados de búsqueda.
👉 Solución: consolidar en una sola versión mediante canonical o redirección 301, según el caso. Si el problema viene de un CMS que genera múltiples versiones de cada post, hay que actuar en la configuración de origen.
🚨 Señales de que tienes duplicidad técnica en tu web
Varias URLs posicionando para la misma intención
⚠️ Problema: Dos o más URLs de tu web aparecen en Google para las mismas búsquedas, compitiendo entre sí y dividiendo la autoridad.
👉 Solución: consolidar en una sola URL mediante canonical o redirección, dependiendo de si el contenido se mantiene o se elimina. Este problema también puede confundirse con canibalización SEO, aunque el origen es diferente.
La diferencia entre canibalización SEO y duplicidad técnica es importante: la canibalización ocurre cuando varias páginas distintas compiten por la misma keyword; la duplicidad técnica ocurre cuando la misma página existe en varias URLs.
Páginas similares indexadas sin intención distinta
⚠️ Problema: Google tiene indexadas páginas con contenido prácticamente idéntico que no aportan valor diferenciado ni responden a intenciones de búsqueda distintas.
👉 Solución: diferenciar el contenido si tiene sentido mantener ambas páginas, o eliminar la versión menos relevante y redirigir hacia la principal. La relevancia temática concentrada en una sola URL posiciona mejor que dividida en varias.
Rankings inestables o contenidos que no consolidan
Un patrón frecuente en webs con duplicidad técnica son los rankings inestables: páginas que suben y bajan de posición sin motivo aparente, o contenidos que llevan meses sin terminar de consolidarse a pesar de tener backlinks y buenas señales. Esto ocurre porque las señales se reparten entre versiones y ninguna acumula suficiente peso para estabilizarse.
🔧 Cómo solucionar la duplicidad técnica paso a paso
Paso 1: Definir una URL principal para cada contenido
✅ Acción: elegir la versión canónica de cada página.
Antes de cualquier corrección, hay que decidir qué URL es la versión oficial de cada contenido. Esa versión será a la que apunten todos los canonical, todas las redirecciones y todos los enlaces internos. Sin esta decisión previa, el resto de correcciones no tienen una dirección clara.
Paso 2: Implementar redirecciones correctamente
✅ Acción: unificar accesos mediante redirecciones 301.
Una vez definida la URL principal, todas las versiones alternativas deben redirigir hacia ella con una redirección 301. Esto consolida la autoridad que llegaba a las versiones duplicadas y la concentra en la versión oficial. Evita las cadenas de redirecciones, que diluyen el traspaso de autoridad.
Paso 3: Usar correctamente la etiqueta canonical
✅ Acción: indicar a Google la versión preferida de cada página.
El canonical es una señal, no una orden. Google puede ignorarlo si hay incoherencias. Para que funcione bien, el canonical tiene que apuntar siempre a la versión accesible, indexable y coherente con el resto de señales de la página. Un canonical que apunta a una URL con noindex o que está en redirección no aporta nada.
Paso 4: Controlar parámetros y filtros
✅ Acción: evitar que parámetros generen páginas indexables innecesarias.
Para parámetros de seguimiento (UTM, etc.), asegurarse de que no se indexan. Para filtros de ecommerce, decidir qué combinaciones merecen indexarse y usar noindex o canonical en el resto. Una arquitectura de URLs limpia desde el origen evita que este problema se acumule con el tiempo.
Paso 5: Revisar la arquitectura general de la web
✅ Acción: simplificar la estructura y evitar que el problema vuelva a aparecer.
La duplicidad técnica suele ser un síntoma de una arquitectura mal definida desde el principio. Corregir los síntomas sin revisar la estructura es solucionar el problema hoy para que vuelva mañana. Una arquitectura limpia, con jerarquía clara y URLs coherentes, es la mejor prevención a largo plazo. Esto forma parte de cualquier
Una arquitectura limpia es también la condición para que el linkbuilding white hat funcione correctamente: los backlinks transmiten autoridad hacia URLs concretas, y si esas URLs tienen versiones duplicadas, la autoridad se fragmenta.
🚫 Errores comunes al intentar solucionar duplicidad técnica
Usar canonical sin lógica
⚠️ Problema: El canonical apunta a URLs que tienen noindex, que están en redirección o que no son la versión correcta, lo que hace que Google lo ignore.
👉 Solución: revisar que cada canonical apunta a una URL accesible, indexable y coherente. Un canonical mal implementado es peor que no tenerlo porque genera contradicciones que confunden al rastreador.
Bloquear con robots.txt en lugar de solucionar la estructura
⚠️ Problema: Se bloquea el acceso a URLs duplicadas con robots.txt pensando que así se elimina el problema, pero las URLs siguen existiendo y pueden seguir recibiendo enlaces.
👉 Solución: el robots.txt evita el rastreo pero no la indexación si la URL ya estaba indexada o tiene enlaces apuntando a ella. La solución correcta es redirigir o consolidar mediante canonical, no bloquear.
No revisar todas las versiones del sitio
⚠️ Problema: Se corrige la duplicidad en las páginas visibles pero se ignoran las versiones generadas por el CMS: archivos de autor, de fecha, páginas de etiquetas o URLs con parámetros.
👉 Solución: hacer una revisión manual completa usando site: en Google y probando las versiones del dominio. La duplicidad oculta en el CMS es la más frecuente y la que más tarda en detectarse si no se busca activamente.
⚡ Resumen: problemas frecuentes y soluciones directas
- URLs múltiples del mismo dominio → unificar con redirecciones 301 hacia una sola versión.
- Parámetros de URL indexables → controlar con canonical o excluir de la indexación.
- Contenido similar en varias URLs → diferenciar el enfoque o consolidar en una sola página.
- Versiones HTTP/HTTPS sin redirección → forzar una única versión con redirección de servidor.
- Archivos de CMS no controlados → revisar configuración y aplicar noindex donde no aporte valor.
Si después de aplicar estas correcciones el perfil de backlinks de tu web sigue mostrando señales de dispersión o los resultados no mejoran, puede ser el momento de revisar el estado off-page en profundidad.
✅ Para ir terminando: la duplicidad técnica se detecta, se corrige y se previene
La duplicidad técnica no es un problema de contenido: es un problema de estructura. Cuando varias URLs representan lo mismo, Google reparte señales y el posicionamiento se debilita de forma silenciosa pero constante.
La buena noticia es que la mayor parte de estos problemas se pueden detectar sin herramientas de pago, con búsquedas simples en Google y comprobaciones manuales de las versiones del dominio. Y una vez detectados, las soluciones son técnicamente sencillas: redirecciones, canonical y control de la configuración del CMS.
Lo importante es no dejar que se acumulen. Una arquitectura limpia desde el origen es la mejor prevención, y parte de cualquier estrategia SEO que quiera ser sostenible a largo plazo. Si quieres revisar el estado técnico y off-page de tu web de forma integral, los servicios de linkbuilding incluyen análisis de la estructura que recibe los backlinks, porque de nada sirve construir autoridad sobre una base técnica con grietas.
Preguntas frecuentes sobre duplicidad técnica en SEO
¿La duplicidad técnica penaliza directamente en Google?
No genera una penalización manual, pero sí tiene un impacto negativo en el posicionamiento. Google reparte la autoridad entre las versiones duplicadas, lo que debilita a todas. El efecto es una pérdida de posicionamiento progresiva, especialmente visible en contenidos que deberían consolidarse y no lo hacen.
¿Es suficiente usar canonical para solucionar la duplicidad?
El canonical es una señal, no una solución definitiva. Google puede ignorarlo si hay incoherencias técnicas. Para soluciones más robustas, las redirecciones 301 son más efectivas porque no dejan opción: el rastreador solo accede a la versión correcta. El canonical tiene sentido cuando no es posible redirigir, como en el caso de URLs con parámetros que deben mantenerse.
¿Cómo afecta la duplicidad técnica al linkbuilding?
Afecta directamente porque los backlinks que apuntan a versiones duplicadas transmiten autoridad a URLs que no son la principal. Si tienes enlaces apuntando a la versión HTTP y tu web ha migrado a HTTPS sin redirección, esos enlaces no suman correctamente.
¿Qué diferencia hay entre duplicidad técnica y canibalización SEO?
La duplicidad técnica ocurre cuando una misma página existe en varias URLs: el contenido es idéntico pero el acceso es diferente. La canibalización ocurre cuando varias páginas distintas, con contenido diferente, compiten por la misma keyword. Ambos problemas diluyen la autoridad, pero tienen causas y soluciones distintas.
¿Puedo detectar toda la duplicidad sin herramientas de pago?
Puedes detectar la mayor parte: versiones del dominio, URLs con parámetros, títulos duplicados en Google y archivos de CMS. Para una detección sistemática y completa de todas las URLs indexadas y sus versiones, las herramientas de rastreo como Screaming Frog (versión gratuita hasta 500 URLs) o Google Search Console ayudan a completar el análisis manual.